

Dataset Description
Updated:2025-09-25 (Latest)
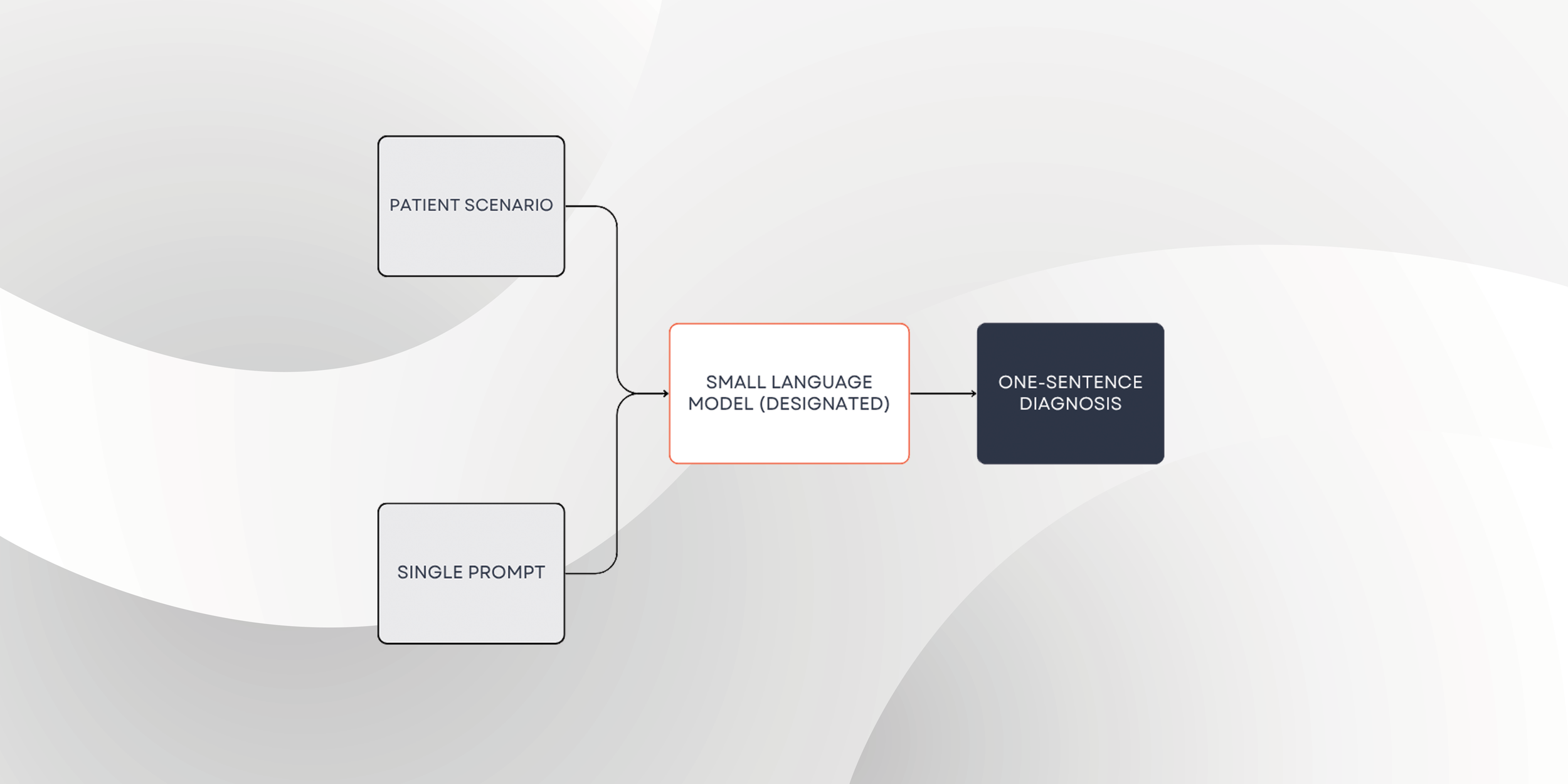
In this competition, you will design a single prompt to guide small language models (<70B parameters) in generating accurate, one-sentence medical diagnoses from clinical case reports.
100 cases were randomly selected from case reports published in The New England Journal of Medicine (NEJM) and The Journal of the American Medical Association (JAMA) journals between 2024 and 2025 as complex cases, and 100 cases were randomly selected from the MedQA database as common cases. Together, these form the dataset for this competition. These cases vary in complexity, presentation, and medical specialty, simulating the diagnostic challenges faced in clinical practice.
Each case is provided as a single, detailed narrative in natural language. Your task is to engineer a prompt that, when combined with each case report and fed into a language model, will elicit the most accurate one-sentence diagnosis.
Files Provided on Kaggle
Case_Report.csv - An Excel file containing the full set of clinical case reports.
Medprompt Hackathon 2025 LLM on Kaggle Guideline.pdf - A comprehensive guide on setting up an LLM environment on Kaggle using Jupyter Notebook. (Also available here)
4 ready-to-import Jupyter Notebooks, each pre-configured for a designated language model:
gemma3-14b-kaggle-notebook-general.ipynb
gemma3-27b-kaggle-notebook-general.ipynb
qwen3-14b-kaggle-notebook-general.ipynb
deepseek-r1-14b-kaggle-notebook-general.ipynb
Columns (Case_Report.csv)
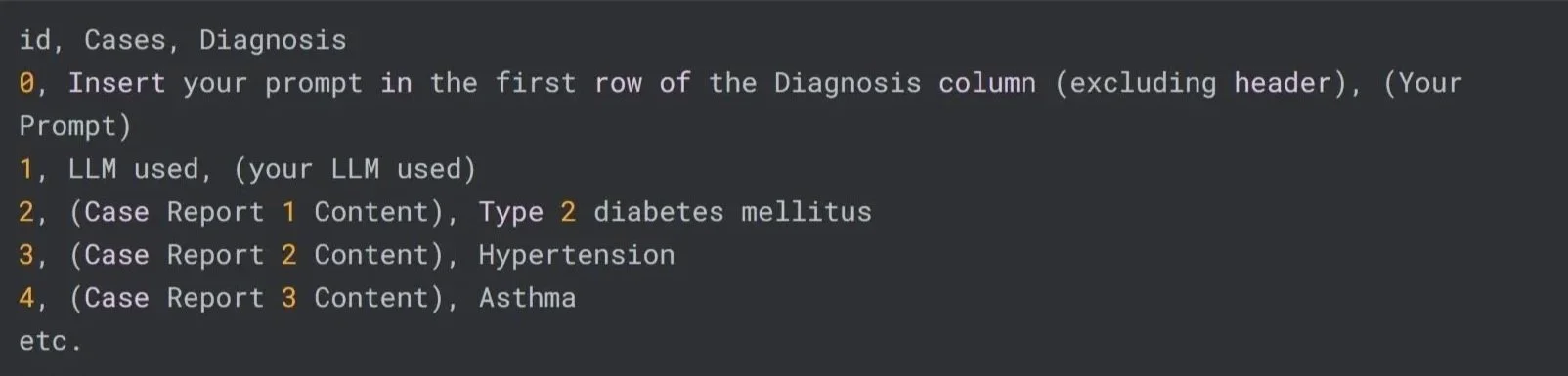
id- A unique identifier (number) for each case report.Cases- The full narrative clinical case report describing a unique patient scenario.Diagnosis- The one-sentence diagnosis (string) corresponding to the case report. This field should be filled in by participants based on the diagnosis generated by their prompt and model for each case.The first row of Case_Report.csv is reserved for your prompt.
The second row is reserved for you to insert the model name used.
The remaining rows correspond to each clinical case report in the dataset.
Submission File
Your submission must be a CSV file with a header, containing a row for each clinical case report in the test set:
Tools and Resources
Designated LLM: Specific small language models (<70B parameters) have been designated for use in this competition. Participants are required to use these models to ensure a fair comparison of prompt effectiveness.
4 models are selected for this competition:Gemma3:27B
Gemma3:12B
Qwen3:14B
DeepSeek R1:14B
Jupyter Notebook: To streamline your workflow, we have provided ready-to-use Jupyter notebooks. These notebooks demonstrate how to load the dataset, apply your prompt to the cases, run the LLM, and format your output for submission. (For fair prompt validation after the competition, it is strongly recommended to use these notebooks or strictly follow their LLM settings if running locally. If you modify the LLM beyond the default settings, we may not be able to validate your prompt.)
Getting Started Guide: A step-by-step guide is included in the competition datasets. This guide walks you through setting up an LLM environment on Kaggle, using the Jupyter notebook, and submitting your results.
All required files, including the dataset, notebook, and guide, are available in the Competition Datasets section on Kaggle.
Evaluation
Submissions will be evaluated based on how closely your predicted diagnosis matches the ground truth for each case report. For each case, if your answer is sufficiently similar to the correct diagnosis, it will be considered a match.
Scoring Details
Each case is marked as a match or no match depending on the similarity between your answer and the ground truth.
Your final score is based on the match rate: the proportion of case reports where your answer is considered a match.
In cases of similar match rates among multiple teams, minor differences in answer similarity will be used to further differentiate score.
Answers are compared in a case-insensitive manner.
Leading/trailing whitespace is ignored.
Blank or missing answers will not be counted as a match.
How the Score is Calculated
Matches and similarity are combined into a single score:
Final Score = Accuracy × Average Similarity
Accuracy = (# of correct predictions ÷ total predictions)
Average Similarity = (mean similarity across all cases)
Correctness Threshold: If similarity ≥ 0.8, the prediction is counted as correct.
Each predicted diagnosis is compared to the ground truth at the character level, and assigned a similarity score between 0.0 and 1.0, where higher values indicate stronger matches:
- 1.0 means the answers are identical.
- 0.0 means completely different.
Example
